
「写」の簡体字が正しく表示されない?!
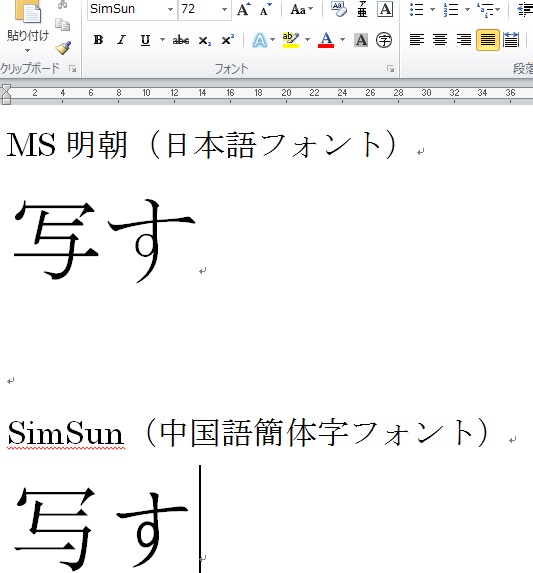
中国語を教室で学んだことがある人は、教員から「写」という字は日本語の漢字と簡体字では微妙に書き方が異なりますから気をつけてくださいと言われたことがあるでしょう。日本語の漢字では「写」の最後の一画の横棒は突き抜けますが、簡体字では突き抜けません。ところが、中国語簡体字書かれたWebページを見た時に、「写」の字が日本語と同じ字形になっていたり、あるいは自分で中国語簡体字で「写」を入力した時に、変換されてきた文字が日本語と同じ字形で表示されたことがあるかもしれません。
パソコンは文字に文字コードと呼ばれる番号を振って管理しています。パソコンで現在使われているUnicodeという文字コードでは、日本語の漢字の「写」と中国語簡体字は同じ文字コードが振られています。つまりパソコンにとっては最後の横棒が突き抜けるか突き抜けないかは関係なく、同じ文字ということになります。日本語がメインのパソコンを使っていると、中国語簡体字のフォントが指定されていないと、たとえ中国語簡体字で入力していても、日本語の漢字が優先的に表示されることになります。
ここでちょっと実験をしてみましょう。ワープロソフトのWordを起動し、新規文書を開いて、日本語で「写す」と入力します。違いがわかりやすいように文字を大きくしておきます。次に入力した「写」を選択して、中国語のフォント、WindowsであればSimSunやSimHei、MacOS Xであれば宋体や黑体を指定します。すると、「写」の字は、最後の横棒は突き抜けない字形、すなわち中国語簡体字の字形に変化しませんか?
時間を20年ほど前に戻しますと、Windows95の時代には1つの文書に日本語と中国語を混在させることは原理的には不可能でした。日本語は日本語、中国語簡体字は中国語簡体字、中国語繁体字は中国語繁体字とそれぞれ異なる文字コードを使用していたからです。Windows95の時代にも日本語と中国語の混在を実現しているソフトはあるにはありましたが、トリッキーな仕組みを使っており、印刷はできても、データの互換性に乏しい方法でした。Unicodeは世界の様々な言語を一つの文字コードで表す仕組みです。Unicodeのおかげで、1つの文章に複数の言語を混在させることができるようになり、多言語を含むデータのやりとりができるようになりました。ただ、問題点がないわけでもありません。「写」のように、漢字を使用しているそれぞれの国や地域でわずかに字形が異なる字がある場合、それを1つのコードに統合しているのです。したがって冒頭に述べたような現象が起こります。
この著者の最新の記事

関連記事






週間ランキング
-
 スマートフォンで中国語入力をするには?―iPhoneとAndroid...
目次
iPhoneで中国語入力をONにする
...
スマートフォンで中国語入力をするには?―iPhoneとAndroid...
目次
iPhoneで中国語入力をONにする
...
-
 中国語Q&A:「〜さん」は中国語でどう訳しますか?...
Q:教科書に“老周”とか“小王”とかが出てきた時に、先生は周...
中国語Q&A:「〜さん」は中国語でどう訳しますか?...
Q:教科書に“老周”とか“小王”とかが出てきた時に、先生は周...
-
 オンラインで使える中国語音節表まとめ...
パソコンやスマホで利用できる中国語音節表のまとめ。中国語...
オンラインで使える中国語音節表まとめ...
パソコンやスマホで利用できる中国語音節表のまとめ。中国語...
-
 Web漫画で中国語
1.Webで日本の漫画の中国語訳を読む
初級の授業を修了...
Web漫画で中国語
1.Webで日本の漫画の中国語訳を読む
初級の授業を修了...
-
 学習素材:中国語の語順
中国語は語順が大事な言語です。以前教えていたが学生が、「中国...
学習素材:中国語の語順
中国語は語順が大事な言語です。以前教えていたが学生が、「中国...
-
 中国語医療通訳トレーニング:第11回 糖尿病/糖尿病...
今回は、糖尿病の医療通訳です。
50代男性、健康診断で血糖...
中国語医療通訳トレーニング:第11回 糖尿病/糖尿病...
今回は、糖尿病の医療通訳です。
50代男性、健康診断で血糖...
-
 基本文法練習プリント1:“是”
授業をどうしても休まなくては行けない時に作成した自習プリント...
基本文法練習プリント1:“是”
授業をどうしても休まなくては行けない時に作成した自習プリント...
-
 日中比較年表
中国語で0~9の一桁の数字を習ったら発音練習のついでに中国の...
日中比較年表
中国語で0~9の一桁の数字を習ったら発音練習のついでに中国の...
-
 “下午好”は午後のあいさつ?
最近は中国でも「スターバックスコーヒー」をいろいろな町で見掛...
“下午好”は午後のあいさつ?
最近は中国でも「スターバックスコーヒー」をいろいろな町で見掛...
-
 中国語医療通訳トレーニング:第3回 整形外科/骨科(1)...
今回は、前後半に分けて整形外科の診察の場面を見ていきます。...
中国語医療通訳トレーニング:第3回 整形外科/骨科(1)...
今回は、前後半に分けて整形外科の診察の場面を見ていきます。...
-
 【中国語会話】CS4-4201 写真を撮ってもらう...
写真を撮る際、日本語では「ハイ、チーズ」と言うのが一般的で...
【中国語会話】CS4-4201 写真を撮ってもらう...
写真を撮る際、日本語では「ハイ、チーズ」と言うのが一般的で...
-
 【素材】みんなで集めよう印刷できる学習素材...
素材の紹介:授業や自習など様々なシーンで印刷して利用できるプ...
【素材】みんなで集めよう印刷できる学習素材...
素材の紹介:授業や自習など様々なシーンで印刷して利用できるプ...
-
 中国料理レシピサイトまとめ(中国語)収集中!...
美食杰
http://www.meishij...
中国料理レシピサイトまとめ(中国語)収集中!...
美食杰
http://www.meishij...
-
 中国語医療通訳トレーニング:第1回 受付/挂号处...
体、病気、ケガに関する表現は、私たちの健康に直結するとても大...
中国語医療通訳トレーニング:第1回 受付/挂号处...
体、病気、ケガに関する表現は、私たちの健康に直結するとても大...
-
 書いて覚える簡体字:サンプル
書いて覚えるキクタン中国語ワークシートというのを公開してい...
書いて覚える簡体字:サンプル
書いて覚えるキクタン中国語ワークシートというのを公開してい...












 中国語検定対策WEB...
中国語検定対策WEB...